OCR
What is OCR?
iPaaS OCR provides a simple way of parsing images and multi-page PDF documents (PDF OCR) and getting the extracted text results returned in Searchable PDF and a JSON format.
A searchable PDF file is a PDF file that includes text that can be searched upon using the standard Adobe Reader “search” functionality. In addition, the text can be selected and copied from PDF.
If user wants to convert scan PDF to searchable PDF, then user can select mapping type as ’OCR’
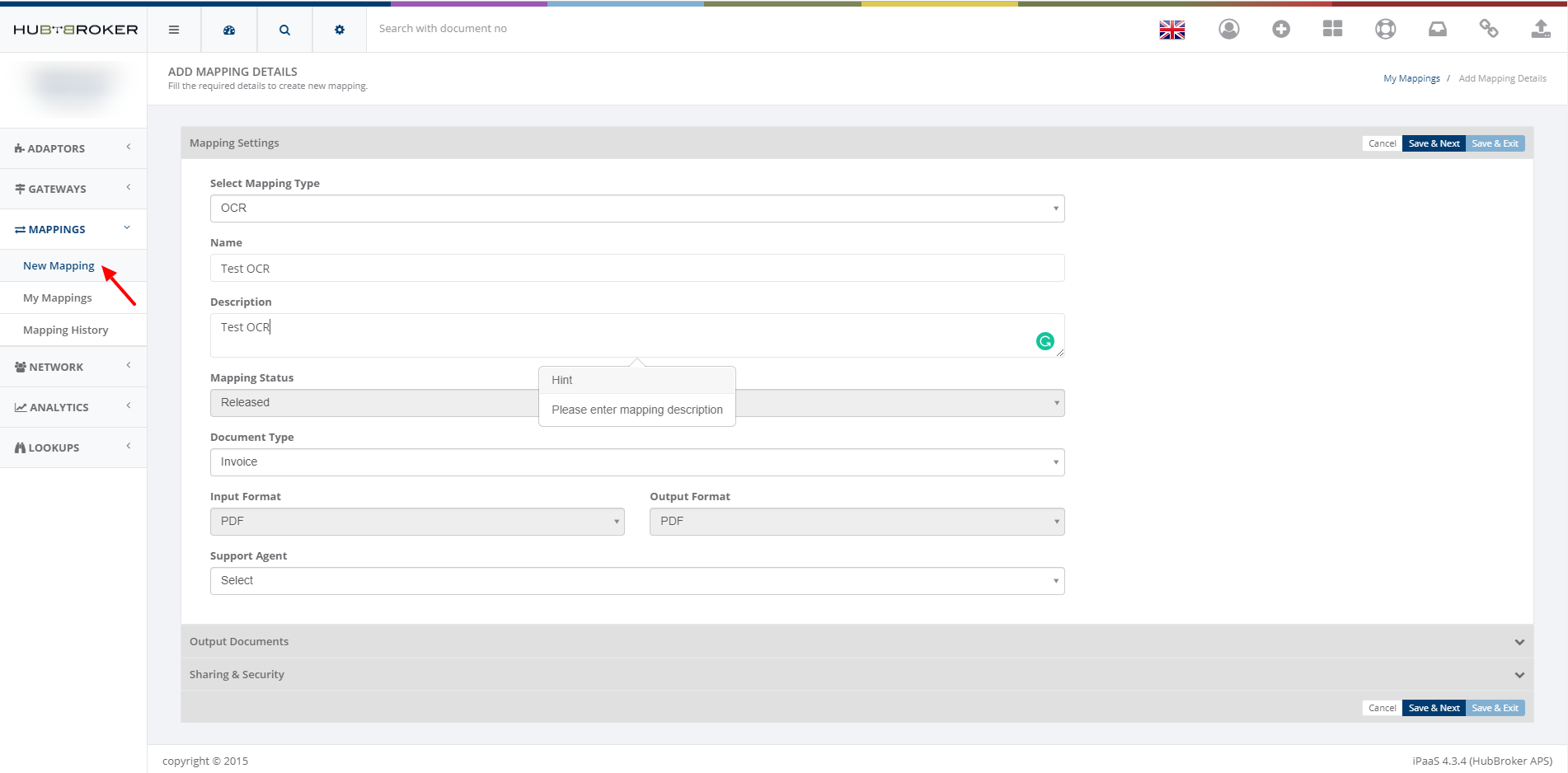
How HubBroker OCR mechanism converts scan PDF into Searchable PDF?
User send PDF file on the email address for e.g. eriks.ocr.order@hubbroker.net
An OCR Engine convert the scan PDF into Searchable PDF (or Digital PDF).
Download the Searchable PDF from adaptor history.
After transformation, you can see text in red font in searchable PDF.
Texts are visible so that the user can compare that data extracted properly or not.
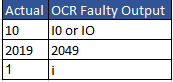
Disadvantage of OCR
- Low-quality scans are less likely to be read by OCR software.
- Some faulty output you will see after OCR transformation